Accelerating Geo-distributed Learning with Client Transfers
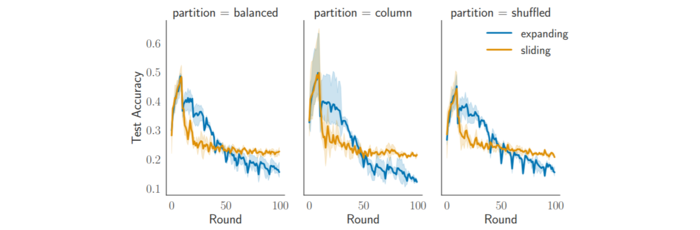
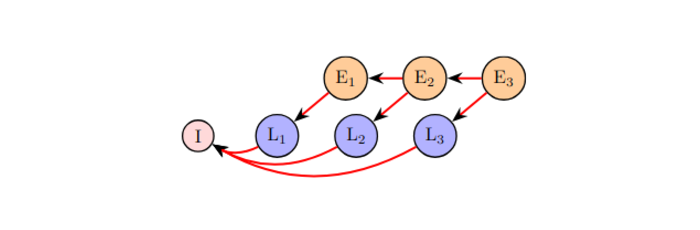
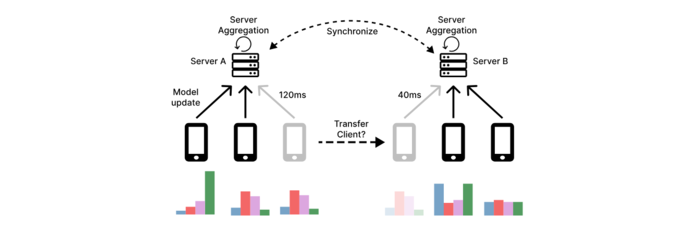
Nomad is the first dynamic client transfer framework for multi-server FL, reallocating clients based on network conditions and data alignment to reduce latency and improve learning. Unlike static assignments, Nomad enables flexible migration during training. Experiments show accuracy improvements of up to 31.8 points in join-only settings and 18.8 points under churn, consistently surpassing strong baselines and scaling well across geographic deployments.