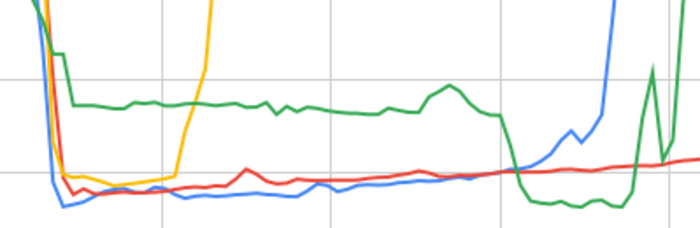
Minimizing idleness in Spark Clusters
The GDelt database 1, on 18-11-2019, consists of 492,618 segments. Processing the top 10 most mentioned topics for each date on the whole data set would take a long time. Using clusters in the cloud, like AWS EMR, significantly decreases up the needed computation time but might be costly. To make the best use of the clusters on AWS EMR a minimization of the idle time of the machines is desired. ...