MemA: Fast Inference of Multiple Deep Models
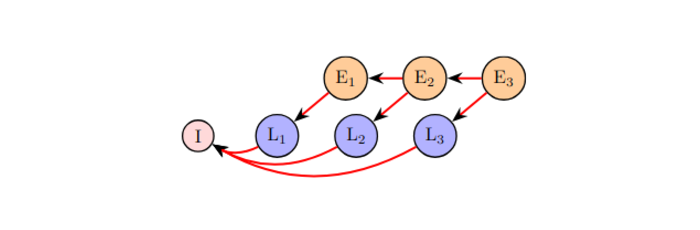
The paper introduces EdgeCaffe, a framework for exploring scheduling policies in multi-inference DNN jobs on resource-constrained edge devices. It proposes MemA, a memory-aware policy that improves execution time by up to 5x without additional resources, based on layer-specific memory demands.